반응형
아스키코드 (ASCII Code)
표준
미국 정보 교환 표준
즉 미국을 위한 미국에 의한 미국의 코드
Character Set
SBCS : Single Byte Character Set
SBCS 란?
SBCS는 하나의 문자세트에 부여된 글자 값이 Single Byte,
즉 0-255의 범위 내에 있음
우리가 잘 알고있는 ASCII 또는 ISO-8859-1 문자 세트가 여기에 속함
0x20부터 0x7F까지는 화면 출력이 가능한 문자세트를 정의하고 있음
ASCII(American Standard Code for Information Interchange)
ASCII는 최초의 문자열 인코딩
7 bit로 구성되어 있으며, 영어를 위한 문자, 숫자, 특수문자, 기호 등 128개 문자를 표현할 수 있음
'영어를 위한 문자' (ASCII의 A가 'American'인 점을 주목)
ASCII에서는 영어만을 고려하여 만들어졌고, 일본어 중국어 등 다른 언어는 표현이 불가능함.
Byte 크기
1 Byte 사용
장점
아스키코드는 모든 문자 하나가 1byte를 차지함
알파벳(대문자 , 소문자)들과 확장 문자를 포함하여 총 256개를 넘지 않는 문자로 이루어짐
이는 1 바이트(는 256가지의 표현이 가능)를 가지고 충분히 표현할 수 있기에 1 바이트의 char형을 사용해서 표현을 할 수 있음
단점
아스키 문자 코드 만으로는 한글이나 일어 등의 다른 문자를 표시할 수 없음
SBCS로는 프로그램을 국제화(Internationalization 혹은 간단하게 i18n)할 수 없음
변수
일반 문자열과 변수 사용
멀티바이트코드
표준
MicroSoft에서 만든 표준
세계표준으로 합의가 이루어지지 않은 윈도우에서 개발된 코드
Character Set
MBCS : Multi Byte Character Set
MBCS 란?
SBCS와 DBCS를 묶어놓은 문자세트를 의미
DBCS의 문자세트에는 거의 SBCS의 문자가 포함되므로,
우리가 말하는 DBCS는 사실은 주로 MBCS를 의미함
DBCS 란?
DBCS는 하나의 문자세트에 부여된 글자값이 두 바이트
즉 0-65535의 범위 내에 있음을 말함
이는 원래의 8비트에서 또 다른 8비트를 단순히 확장한 것
DBCS는 8비트로 처리할 수 없을 정도로 문자의 종류가 많은 중국, 한국, 일본 그리고 대만 등에서 주로 사용
ANSI, UTF-8 포함
ANSI(American National Standard Institute)
ANSI는 8bit로 구성되어 있으며 256개의 문자를 표현할 수 있음
ANSI는 ASCII의 확장판 : 그 이유는 ASCII에서 1bit를 더 사용한 것이기 때문
ANSI의 앞 7bit는 ASCII와 동일하고, 뒤에 1bit를 이용하여 다른 언어의 문자를 표현
그런데 새로 추가 된 128개 문자로는 모든 언어의 문자를 표현할 수 없음.
그래서 생긴 개념이 CodePage 임.
각 언어별로 Code 값을 주고, Code마다 다른 문자열 표를 의미하도록 약속을 함.
쉽게 생각하면 아래와 같이 설명할 수 있음.
ANSI = ASCII(7bit) + CodePage(1bit)
코드페이지는 아래서 설명.
Byte 크기
한글 : 2Byte
영어 : 1Byte
장점
멀티바이트 문자 집합은 특정 문자 집합마다의 코드페이지가 존재하여
영어 이외의 나라 문자 표현 가능
코드 페이지란? (Code Page)
마이크로소프트 테크넷에 게재된 각종 컴퓨터용 코드
특정 문자 인코딩 테이블을 위해 쓰이는 전통적인 IBM 용어
문자 인코딩 테이블은 0부터 255까지의 정수를 표현하는
단일 옥텟(Octet, 바이트)이라고 불리는 일련의 비트들이 특정한 문자와 결합하여 도표화(Mapping)한 것
코드페이지 한글 KSC5601 예)
문자세트의 처음 부분인 0x00부터 0x7E 까지는 ASCII와 동일
이러한 배열은 중국, 일본, 대만에도 마찬가지며 나중에 설명할 Unicode에서도 마찬가지
DBCS의 첫 번째 바이트 = 리딩 바이트(Leading Byte)
DBCS의 두 번째 바이트 = 트래일링 바이트(Trailing Byte)
첫 번째 128 문자는 ASCII로 되어있고 나중 128 문자는 각 언어마다 다르게 지정되어있음
단점
ASCII를 제외하고는 각 DBCS들이 모두 다른점이 단점
예)
흔히 사용하는 strlen()는 MBCS에서 더 이상 직접 사용할 수가 없음
즉, strlen()은 문자의 수를 반환하게 되는데,
SBCS에서는 문자의 수가 바이트 수와 일치하므로 strlen()의 반환값은
사실 해당 문자가 차지하는 바이트의 숫자일 수도 있음
하지만 MBCS에서는 문자의 수와 그 문자가 차지하는 바이트의 수는 나라의 언어마다 값이 다르므로
strlen()으로 문자의 수를 계산할 수 없음
I/O에 연관된 문자의 처리에 해당되는 프로그램의 모든 로직을 일일이 DBCS와 SBCS을 염두에 두고 개발해야함
자칫 실수하면 프로그램상의 BUG(버그 또는 오류)를 가져오는 요인이 됨
MBCS를 사용하면 프로그램상의 난이도가 늘어나게됨
변수
일반 문자열과 변수 사용
유니코드
표준
유니코드 협회가 제정
전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준
Character Set
WBCS : Wide Byte Character Set
WBCS 란
SBCS와 DBCS가 공존하는 MBCS와는 달리 모든 코드값이 일괄적으로 16비트로 할당
확장형 문자 집합이라는 의미
Windows 뿐만 아니라, Linux, OS X, Android, IOS 등 다양한 운영체제에서 사용
대표적인 인코딩 방법으로 UTF-8이 있음
Byte 크기
모든 문자 2Byte
장점
유니코드는 지구상에서 통용되는 대부분의 문자들을 담고 있음
2Bytes를 사용하므로 65536 개의 표현 범위 덕분에 아스키 코드가 가지는 한계를 극복
처음 127 문자인 0x0080부터 0x00FE는 국제표준화 ISO8859-1의 순서와 동일하게 배열함
단점
printf , scanf 등의 함수는 유니코드와 맞지 않음.
아스키코드의 char 는 1바이트
유니코드의 char는 2바이트이기 때문
함수 사용을 위해서는 wprint등 새로이 정의된 다른 함수를 사용해야한다.
변수
문자열의 경우 L"" 사용
예)
일반C = "Hello"
유니코드 = L"Hello"
변수의 경우 앞에 w가 붙음
예)
일반 C = char
유니코드 = wchar_t
Visual Studio 인코딩 설정
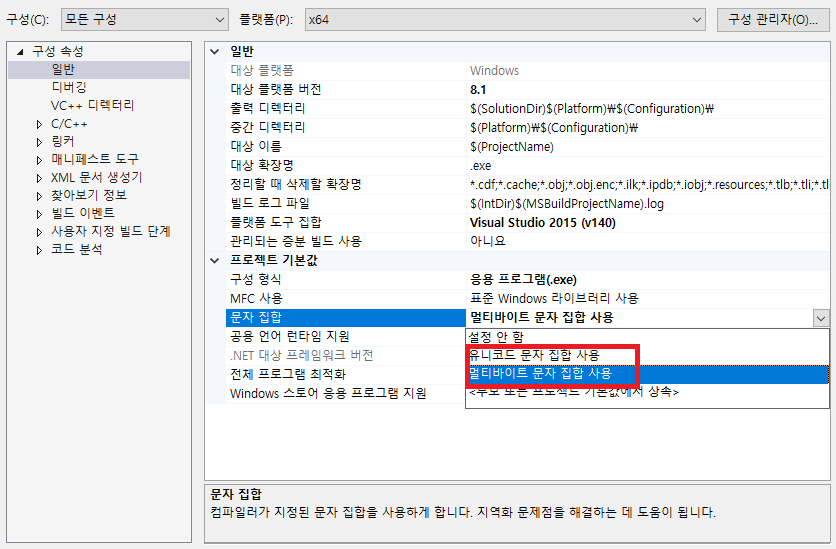
윈도우 유니코드와 멀티바이트코드 코딩
MBCS 는 기본적으로 아스키코드 기반의 프로그래밍을 함
Microsotf 에서는 기존의 아스키 코드를 유지하면서
유니코드 프로그래밍을 지원하기 위해
MBCS 와 WBCS 의 자료형을 구분해서 사용하도록 Visual studio 를 설계했음
유니코드와 멀티바이트 코딩을 동시에 지원하는 프로그래밍으로 tchar.h 가 있음
유니코드와 멀티바이트 코딩을 동시에 지원하기 위해 tchar.h를 사용해서 코딩해야함
tchar.h
아스키코드와 유니코드를 동시 지원할 수 있는 쉬운 개발을 위해 만들어진
Visual Studio 독자적인 헤더파일로 오직 Windows 에서만 사용할 수 있음.
컴파일러 환경에 따라 MBCS, WBCS로 맵핑 시켜줌.
즉 tchar.h 함수를 사용하면 멀티바이트코드와 유니코드를 동시에 고려해서 프로그래밍 가능.
_t 가 붙고 문자열에 _T가 존재함.
_T 란?
유니코드일때 L이 붙고
아스키 코드일때는 붙지 않는 예약어 역할 을 함
|
MBCS
|
WBCS
|
tchar.h
|
|
LPCSTR = const char*
|
LPCWSTR = const wchar_t*
|
LPCTSRT
|
|
LPSTR = char*
|
LPWSTR = wchar_t*
|
LPTSRT
|
|
string = std::basic_string<char>
|
wstring = std::basic_string<wchar_t>
|
tstring = std::basic_string<TCHAR>
|
|
char
|
wchar_t
|
TCHAR
|
|
"ABC"
|
L"ABC"
|
_T("ABC") or TEXT("ABC")
|
|
unsigned int
|
wint_t
|
_TINT
|
|
printf
|
wprintf
|
_tprintf
|
|
scanf
|
wscanf
|
_tscanf
|
|
strcmp
|
wcscmp
|
_tcscmp
|
유니코드 멀티바이트코드 간 변환
atlconv.h 사용
USES_CONVERSION 선언 후 함수 사용
T2A = W2A (LPWSTR - > LPTSTR)
T2W = A2W (LPSTR -> LPTSRT)
A2T = A2W (LPTSTR -> LPWSTR)
W2T = W2A (LPTSTR -> LPSTR)
T2CA = W2CA (LPCWSTR - > LPCTSTR)
T2CW = A2CW (LPCSTR-> LPCTSTR)
A2CT = A2CW (LPCTSTR -> LPCWSTR)
W2CT = W2CA (LPCTSTR-> LPCSTR)
등등
C++ 멀티바이트 문자열을 UTF8 인코딩으로 변환
header : atlstr.h
/*
<Function Description>
멀티바이트 문자열을 UTF8인코딩 함.
멀티바이트 > 유니코드 > UTF8 변환
<parameter>
strMulti : 멀티바이트 문자열
<return>
UTF8 인코딩된 string
*/
std::string multibyteToUTF8(std::string strMulti) {
std::string result;
// 멀티바이트 > 유니코드
int nLen = MultiByteToWideChar(CP_ACP, 0, &strMulti[0], int(strMulti.size()), NULL, NULL);
std::wstring strUni(nLen, 0); //유니코드
MultiByteToWideChar(CP_ACP, 0, &strMulti[0], int(strMulti.size()), &strUni[0], nLen);
// 유니코드 > UTF-8
nLen = WideCharToMultiByte(CP_UTF8, 0, strUni.c_str(), int(strUni.size()), NULL, 0, NULL, NULL);
std::string strUTF8(nLen, 0); // UTF-8
WideCharToMultiByte(CP_UTF8, 0, strUni.c_str(), int(strUni.size()), &strUTF8[0], nLen, NULL, NULL);
result = strUTF8;
return result;
}
C++ UTF8 인코딩 문자열을 멀티바이트로 변환
header : atlstr.h
/*
<Function Description>
UTF-8 문자열을 멀티바이트 인코딩 함.
UTF8 > 유니코드 > 멀티바이트 변환
<parameter>
strMulti : UTF-8 문자열
<return>
멀티바이트 string
*/
std::string UTF8ToMultibyte(std::string strUTF8) {
std::string result;
// UTF-8 > 유니코드
int nLen = MultiByteToWideChar(CP_UTF8, 0, &strUTF8[0], int(strUTF8.size()), NULL, NULL);
std::wstring strUni(nLen, 0); //유니코드
MultiByteToWideChar(CP_UTF8, 0, &strUTF8[0], int(strUTF8.size()), &strUni[0], nLen);
// 유니코드 > 멀티바이트
nLen = WideCharToMultiByte(CP_ACP, 0, strUni.c_str(), int(strUni.size()), NULL, 0, NULL, NULL);
std::string strMulti(nLen, 0); // UTF-8
WideCharToMultiByte(CP_ACP, 0, strUni.c_str(), int(strUni.size()), &strMulti[0], nLen, NULL, NULL);
result = strMulti;
return result;
}
참고
코드 참고
반응형
'OS > Windows' 카테고리의 다른 글
| batch script - error message 출력안하는 설정 (0) | 2022.04.07 |
|---|---|
| batch script - Registry value 값 확인 결과를 File에 저장 (0) | 2022.04.07 |
| Windows SID란? (0) | 2022.01.09 |
| auditpol 사용법 (0) | 2022.01.09 |
| Windows 폴더 경로가 길 경우 단축 시키는 방법 (0) | 2022.01.09 |