Kubernetes kube-proxy Mode 분석
[kubernetes kube-proxy 관련 글 목록]
Kubernetes kube-proxy IPVS Mode 설정
Kubernetes NodePort Networking 분석 (kube-proxy : iptable mode)
Kubernetes NodePort Networking 분석 (kube-proxy : iptable mode)- New version
kubernetes LoadBalancer Networking 분석 (kube-proxy : iptable mode)
목적
kube-proxy mode 종류와
각 종류 동작 원리를 파악해봄.
글을 읽는데 필요한 기초 개념
Netfilter란?
Netfilter란 Network Packet Filtering Framework로
Linux Kernel Space에 위치하여
모든 오고 가는 패킷의 생명주기를 모니터링하고 통제 및 조작할 수 있는 기능을 제공함.
Netfilter는 Netfilter Hook Function을 제공하고 있음.
해당 function을 사용하여 Application을 개발하면 패킷 필터링을 할 수 있도록 해줌.
[Netfilter 5개 Hook point]
NF_IP_PRE_ROUTING: 외부에서 온 Packet이 Linux Kernel의 Network Stack을 통과하기 전에 발생하는 Hook이다. Packet을 Routing하기 전에 발생
NF_IP_LOCAL_IN: Packet이 Routing된 후 목적지가 자신일 경우, Packet을 Process에 전달하기 전에 발생
NF_IP_FORWARD: Packet이 Routing된 후 목적지가 자신이 아닐 경우, Packet을 다른 곳으로 Forwarding하는 경우 발생
NF_IP_LOCAL_OUT: Packet이 Process에서 나와 Network Stack을 통과하기 전 발생
NF_IP_POST_ROUTING: Packet이 Network Stack을 통과한 후 밖으로 보내기 전 발생
[Netfilter Framework를 사용하는 대표적인 Tool]
iptables, ip6tables, ebtables, arptables, ipset, nftables와
추가로 IPVS 가 있음.
[Netfilter Tool 동작 원리]
Netfilter Framework를 사용해서 개발된 Tool의 동작원리를 좀 더 자세히 설명하자면
해당 Tool은 Netfilter 룰 셋 구축을 하는 역할을 수행하는 것임.
Netfilter Hook Function을 사용해서 Rule을 구축하고 패킷을 컨트롤 함.
즉 실질적으로 패킷 필터링은 Linux Kernel에 탑제된 Netfilter Function이 수행함.
참고 :
https://ko.wikipedia.org/wiki/%EB%84%B7%ED%95%84%ED%84%B0
https://xenostudy.tistory.com/245
https://cognitive.tistory.com/99
https://www.netfilter.org/documentation/HOWTO/netfilter-hacking-HOWTO-4.html
iptables이란?
iptables는 Netfilter Framework를 이용하는 대표적인 Tool로
모든 오고 가는 패킷의 생명주기를 모니터링하고 통제 및 조작할 수 있음.
[iptables Chain (Rule)]
기본적으로 Iptables에는 세가지 chain이 있음.
모든 패킷은 INPUT, OUTPUT, FORWARD 이 세가지 chain중 하나를 통과하게 됨.
컴퓨터로 들어가는 모든 패킷은 INPUT chain을 통과하고,
컴퓨터에서 나가는 모든 패킷은 OUTPUT chain을 통과함.
그리고 하나의 네트워크에서 다른 곳으로 보내는 모든 패킷은 FORWARD chain을 통과함.
iptables가 작동하는 방식은 이들 각각의 INPUT, OUTPUT, FORWARD chain에 어떠한 rule을 세우는 지에 따라 달라짐.
[iptables Tables]
iptables는 5가지 Table을 제공하고 있음.
1) fileter Table
packet을 drop할지 전달할지 결정
2) NAT table
Packet NAT(Network Address Translation)을 위한 table. packet의 source/destination address를 변경
3) Mangle Table
Packet의 IP header를 바꿈. Packet의 TTL 변경, Marking하여 다른 iptables의 Table이나 Network tool에서 Packet을 구분 할 수 있도록 함
4) Raw Table
Netfilter Framework는 Hook 뿐만 아니라 Connection Tracking 기능을 제공.
이전에 도착한 Packet들을 바탕으로 방금 도착한 Packet의 Connection을 추적함.
Raw Table은 특정 Packet이 Connection Tracking에서 제외되도록 설정함.
5) Security Table
SELinux에서 Packet을 어떻게 처리할지 결정하기 위한 Table.
IPSET이란?
iptables의 확장 기능인 ipset은 IP들의 집합을 별도로 만들어 관리 할 수 있음.
iptables 유틸을 통해 관리 할 때보다
ipset은 좀 더 다양한 방법으로 많은 IP 셋을 관리 할 수 있는 이점과
인덱싱 데이터 저장 방식으로 인해
iptables로 5000건 이상의 룰셋이 등록 되었을때
시스템의 성능이 급격하게 떨어지는 반면
ipset은 많은 IP 세트를 설정 하더라도 성능이 심각하게 떨어지지 않는 장점이있음.
iptables는 차단하고자하는 룰셋 목록이 많아지면 유지보수가 힘든데
이를 해결하기 위한 방법으로 IPSET을 많이 이용함.
Netfilter/iptables와 tcpdump 우선순위
Wire -> NIC -> tcpdump -> netfilter/iptables
iptables -> tcpdump -> NIC -> Wire
Service Object SessionAffinity 옵션
서비스가 Pod들에 부하를 분산할때
Defualt 알고리즘은 Pod 간에 랜덤으로 부하를 분산하도록 함.
만약에 특정 클라이언트가 특정 Pod로 지속적으로 연결이 되게 하려면
Session Affinity를 사용하면 되는데,
서비스의 spec 부분에 sessionAffinity: ClientIP로 설정해야함.
참고 :
https://lascrea.tistory.com/202
User Space 와 Kernel
Linux에서 System memory는 User Sapce와 Kernel 두 영역으로 나누어짐.
Kernel = 운영 체제의 핵심 명령을 실행하고 커널 공간에서 OS 서비스를 제공함.
User Space = 사용자가 설치 한 모든 사용자 소프트웨어 및 프로세스는 사용자 공간에서 실행됨.
IPVS (IP Virtual Server)란?
IPVS는 Netfilter Framework 기반으로 구현된
Linux Kernel Level에서 동작하는
Layer-4(Transport Layer) Load Balancing Tool임.
Least-Connection 및 Round-Robin을 포함한 다양한 Load Balancing 알고리즘을 지원함.
[IPVS 동작원리]
패킷을 효과적으로 추적하고 Route하기 위해 IPVS는 Linux Kernel에
IPVS 테이블을 생성함.
해당 테이블은 해쉬 테이블임.
IPVS 테이블은 ipvsadm 명령을 사용해서 지속적으로 업데이트가 가능함.
해당 테이블 목록에 따라 특정 End Point로
설정된 Load Balancing 알고리즘을 사용해서 Load Balancing을 수행함.
[ IPVS에서 사용하는 Netfilter Hook Function ]
Netfilter Framework 기반으로 구현되어
제공되는 Netfilter Hook Function 목록 중 아래의 6개를 사용해서 구현함.
ip_vs_remote_request()
ip_vs_local_request()
ip_vs_reply()
ip_vs_local_reply()
ip_vs_forward_icmp()
해당 Hook의 자세한 설명 참고 : https://ssup2.github.io/theory_analysis/Linux_LVS_IPVS/
[IPVS 설정 명령]
ipvsadm
[IPVS Tunneling 종류]
Direct Routing
NAT
IPIP
[IPVS를 사용하는 환경]
Linux에서 제공하는 L4 Load Balancer 솔루션인 LVS( Linux Virtual Server )에서도
Packet Load Balancing 메카니즘으로 IPVS를 사용되고 있음.
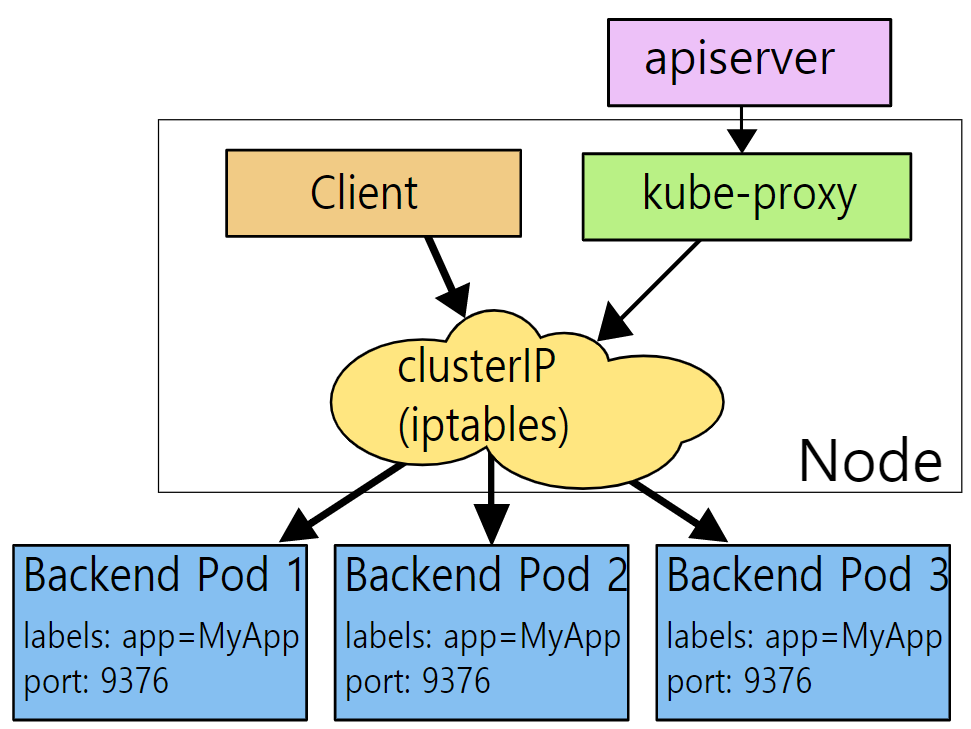
kube-proxy란?
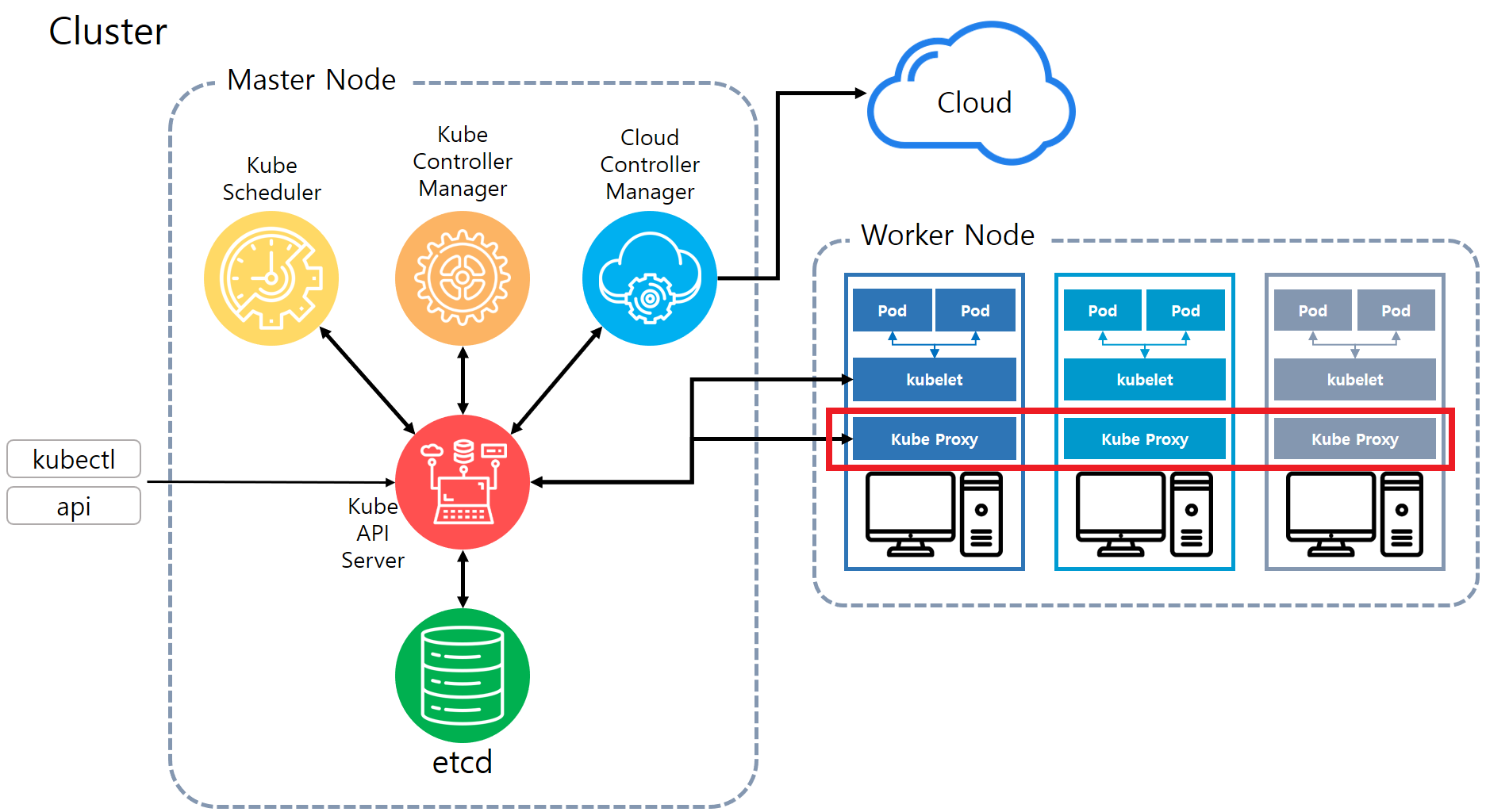
상위 그림의 빨간 네모 부분과 같이
kubernetes cluster를 구성하는 모듈 중 하나로 모든 Worker Node에 배포되어 동작하고 있음.
kube-proxy는 Pod의 Networking을 관리함.
관리자가 kubernetes 네트워크를 설정하기 위해 Service Object를 생성했다면
kubernetes Cluster에서는 해당 Service Object에 설정된것을 반영해서 네트워킹을 관리하기 위해
kube-proxy 모듈을 사용함.
Worker node로 들어오는 네트워크 트래픽을 여러 개의 Pod에 적절한
로드밸런싱 알고리즘을 사용해서 TCP, UDP, SCTP Network Stream을 포워딩함.
즉 network proxy, load balancer 역할을 수행하고 있음.
kube-proxy는 kubernetes cluster를 구성하는 모든 Node에 배포되어야하기 때문에
아래 예제 환경과 같이 Daemonset으로 관리되고 있음.
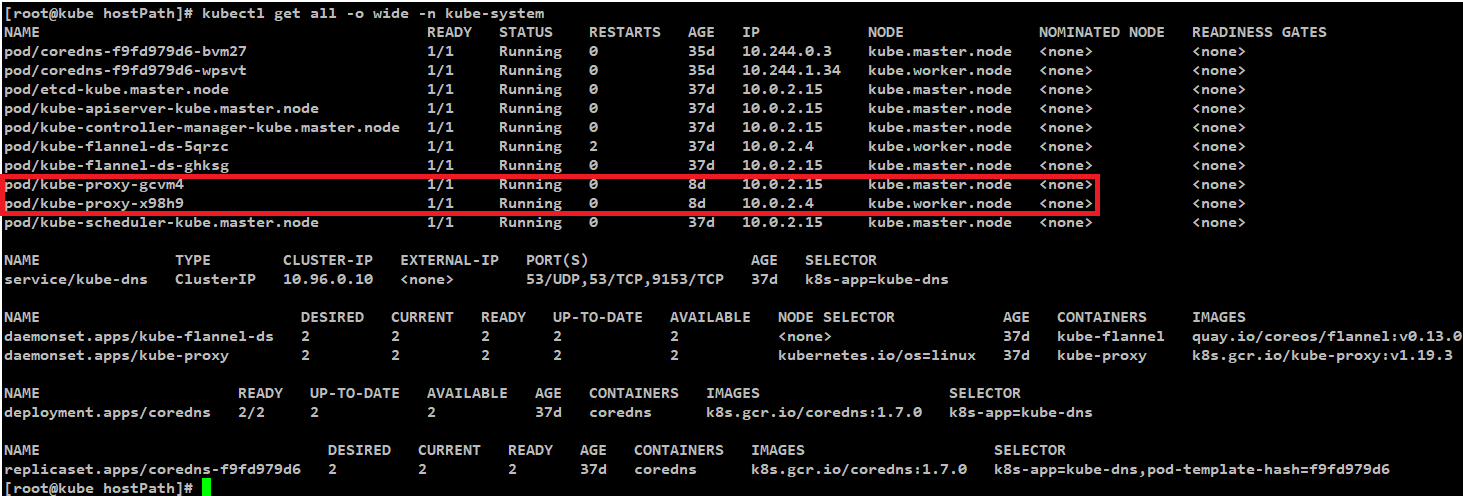
kube-proxy Mode 종류
kube-proxy는 Networking을 효율적으로 관리하기 위해 지속적으로 update를 해왔음.
그래서 다양한 mode를 지원하고 있는데
kubernetes 개발 초기 최초로 default mode로 사용되었던 userspace mode와
userspace의 단점을 보완하고 kubernetes 1.19.2 version 기준 현재 default mode로 제공되고 있는 iptables mode,
그리고 iptables mode 보다 높은 성능을 보여주는 IPVS mode가 있음.
usersapce -> iptables -> IPVS mode 순서로 update 되어 왔음.
모든 Mode의 공통점으로는 Linux Kernal에서 제공되는 Netfiler Framework를 사용한다는 것인데
각 Mode마다 Netfiler Framework를 사용한 Tool 선정 방식에 차이가 있음.
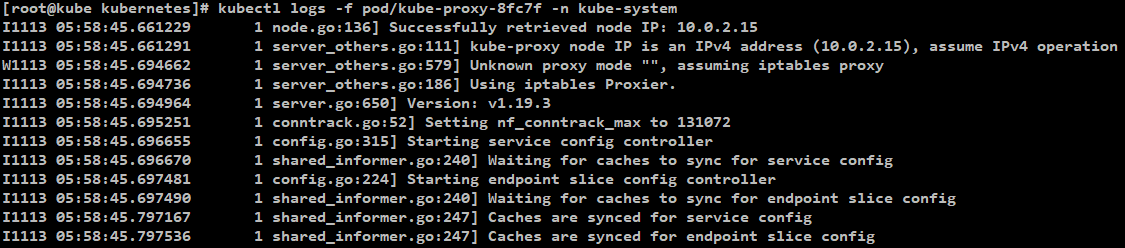
kube-proxy Mode 확인
Kube-proxy는 user space, iptables, ipvs 와 같은 mode로 동작할 수 있음으로
어떤 mode로 동작하는지 확인해야함.
[kube-proxy mode 확인 명령어]
kubectl logs -f [베포되어있는 kube-proxy pod 이름] -n kube-system
예) kubectl logs -f pod/kube-proxy-8fc7f -n kube-system
[kube-porxy mode 확인 결과]
default mode의 경우 : iptables
UserSpace Mode
kubernetes 개발 초기 최초로 default로 사용되었던 mode.
userspace mode에서 패킷 Rule 설정 및 로드밸런싱을 포함한
대부분의 Networking 작업이 kube-proxy에 의해서 직접 수행됨.
현재는 다른 2가지 Mode에 비해 성능이 떨어져서 잘 사용하지 않는 Mode임.
Networking 과정
UserSpace mode의 Networking 준비 단계
[ 1 ]
UserSpace Mode의 kube-proxy는
kube-apiserver와 통신하여 Cluster의 Pod와 Service object의
생성/삭제 상태를 Monitoring 하고있음
[ 2 ]
Serivce Object가 생성되면
kube-proxy는 자신의 Node(Host)에 랜덤한 번호의 Port를 Open하고
위에서 설명했던 Monitoring 결과대로 Service Object에 매칭되는 Pod를 알고있음으로
랜덤한 Port와 목적지인 Pod를 연결시킴.
즉 쉽게 설명하자면 Service Objec의 Cluster IP -> 랜덤한 번호의 Port -> kube-proxy -> 목적지 Pod
[ 3 ]
kube-proxy는 위에서 생성한 proxy용 Port에 대한 네트워크 트래픽을 받기위해
Service Object의 Cluster IP와 Port에 매칭되는 트래픽을
모두 kube-proxy(자신)에게 포워딩 되도록 iptables를 설정함.
즉 kubernetes 관련 네트워크 트래픽은 모두 kube-proxy를 통과하도록 설정함.
UserSpace mode의 Networking 과정
[ 1 ]
Client는 Service Obejct의 Cluster IP로 request 패킷을 보냄.
[ 2 ]
해당 request는 Node(Host)의 iptables 설정으로 생성된 Linux Kernel Netfiler Chain에 적용됨.
[ 3 ]
iptables로 만들어진 Linux Kernel Netfiler Chain에는
ClusterIP Type의 Service Object와 랜덤으로 생성한 Port 간의 매칭 목록이 있음.
이러한 Chain 목록에서 request 패킷이 매칭되는 것이 있으면
request 패킷의 목적지를
"Host IP : 랜덤하게 생성했던 Port"
로 변경함.
[ 4 ]
변경된 패킷 목적지인 Host에 다시 접근하면
해당 requset가 kube-proxy로 전달됨.
[ 5 ]
kube-proxy는 패킷 목적지의 Port 번호를 확인하고
해당 Port(이전에 설명한 랜덤한 Port)와 매칭되는 Pod로 패킷을 전달함.
[ 6 ]
만약 적절한 pod가 다수인 경우는 round-robin 로드밸런싱 방식으로 전달함.
Serivce Object에 SessionAffinity 설정이 되어있었다면 해당 설정을 우선으로 함.
지원되는 로드밸런싱 알고리즘
Round-Robin (라운드 로빈) 1개 지원.
더 자세한 Service Object Type에 대한 Networking 과정
iptables 동작을 자세히 표현한 그림.
UserSpace Mode 의 단점
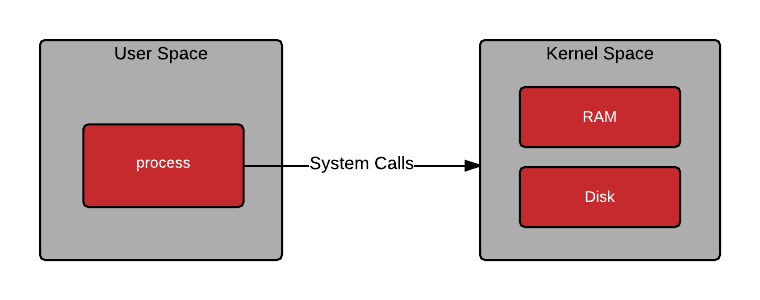
kube-proxy는 Process로 동작하고 있음으로 User Space 영역에서 속함.
그리고 Host의 Networking을 담당하는 Netfilter는 Kernel 영역에 속함.
본질적으로 User Space(Process)의 동작은 Kernel을 통해 이루어짐.
User Space 프로그램은
Process에서 계산을 위한 CPU 시간, I/O작업을 위한 disk, memory 등 이 필요할 때
Kernel에 서비스를 요청하는 시스템 호출해야하는 구조를 가지고 있어서
동작을 위해 User Space에서 Kernel에 액세스 해야하기 때문에
Kernel 자체 서비스에 비해서 훨씬 느림.
UserSpace Mode의 kube-proxy는
로드밸런싱, 패킷 규칙 설정 등 대부분의 Networking 작업을 주로
Process인 kube-proxy 자체에서 컨트롤 하기 때문에
User Space와 Kernel 간 엑세스 해야하는 일이 굉장히 많음.
이러한 이슈때문에 UserSpace Mode의 kube-proxy는
네트워킹 속도가 저하되는 문제점이 있음.
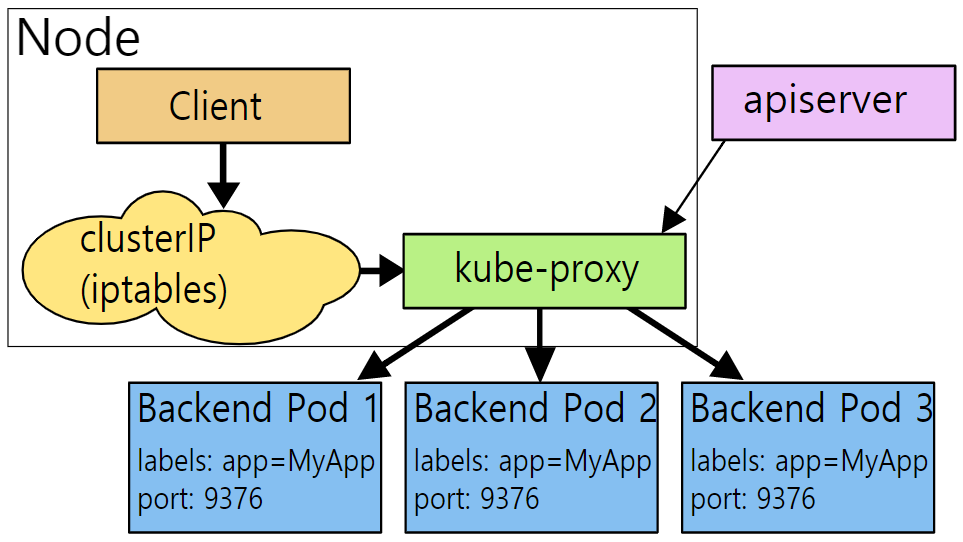
iptables Mode
userspace의 단점을 보완하며 더 발전된 mode로
kubernetes 1.19.2 version 기준 현재 default mode로 설정되어 있음.
userspace mode와는 다르게 kube-proxy가 client로 부터 트래픽을 받지 않고 iptables만 관리함.
iptables를 통해 linux kernel의 Netfilter를 설정하고
client로 부터 오는 request는 Netfilter를 거쳐서 직접 pod로 전달됨.
그래서 userspace mode 보다 빠른 성능을 가짐.
즉 모든 Networking 작업을 iptables/Netfilter로 함.
iptables와 Netfilter
일반적으로 Linux의 방화벽은 iptables가 하는것으로 알고있는데
실제 Linux Networking 동작을 살펴보면
iptables이 패킷을 필터링 하는것이 아님,
실질적으로 패킷 필터링을 하는 것은 Linux kernel에 탑제된 Netfilter임.
iptables은 단지 Netfilter의 룰(정책 or Chain이라고 부름)을 세워줄 뿐임.
Netfilter란 Linux Kernel의 Network 스택에 있는 패킷 필터링 Hook임.
Linux의 모든 패킷은 이러한 kernel에서 동작하는 Netfilter를 통과하게 되는데
iptables와 같은 네트워크 프로세스가 이러한 Netfilter Hook에 등록되어서
Netfilter 룰을 설정할 수 있게 됨.
그래서 설정된 룰에 따라 방화벽 규칙이 구성되어 동작하게 됨.
결론적으로 iptables은 Netfilter 룰 셋구축 툴임.
Networking 과정
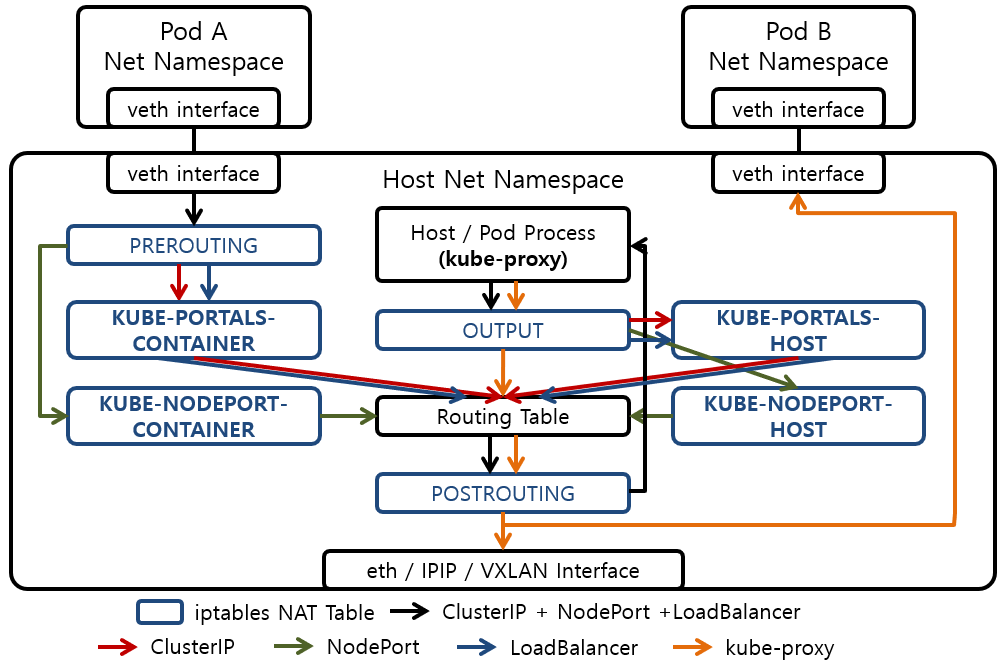
iptables mode의 Networking 준비 단계
[ 1 ]
iptables Mode의 kube-proxy는
kube-apiserver와 통신하여 Cluster의 Pod와 Service object의
생성/삭제 상태를 Monitoring 하고있음
[ 2 ]
Serivce Object가 생성되면
kube-proxy는 iptables 설정으로 해당 Service Object와
Service Object에 매칭되는 Pod정보를 기록한
Netfilter Chain을 생성함.
iptables mode의 Networking 과정
[ 1 ]
Client는 Service Obejct의 Cluster IP로 request 패킷을 보냄.
[ 2 ]
해당 request는 Node(Host)의 iptables 설정에 따라 Linux Kernel Netfiler로 들어옴.
[ 3 ]
Netfilter로 들어온 패킷은 Netfilter Chain 설정에 따라
정해진 Pod로 전송됨.
[ 4 ]
만약 적절한 pod가 다수인 경우는 임의로 선택함
지원되는 로드밸런싱 알고리즘
랜덤 선택
더 자세한 Service Object Type에 대한 Networking 과정
iptables 동작을 자세히 표현한 그림.
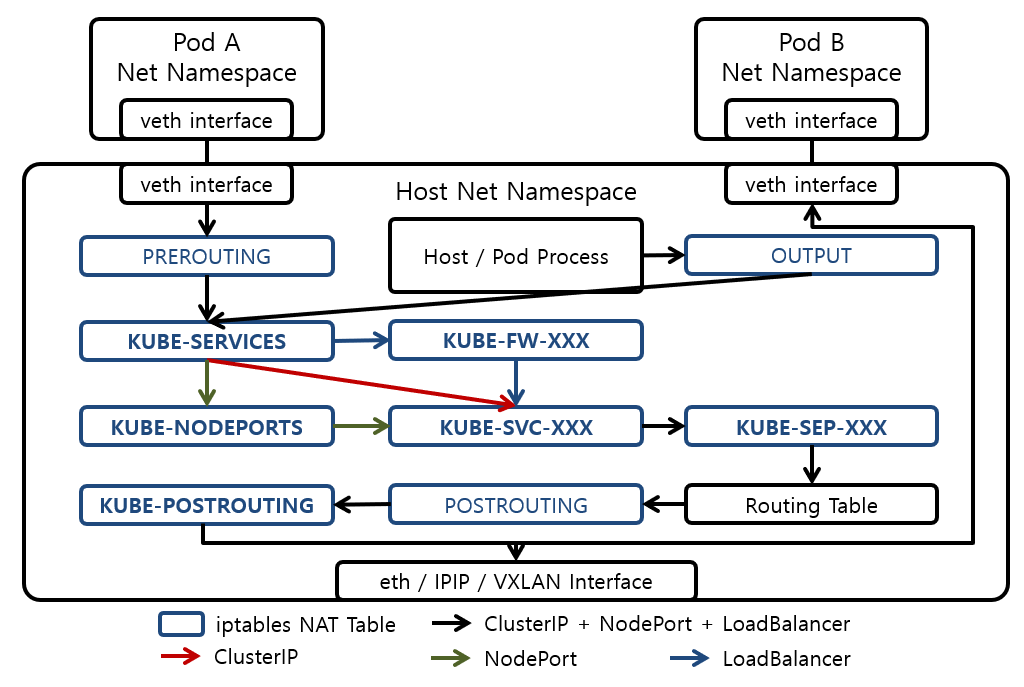
iptables mode의 단점
[1]
UserSpace Mode에서는 Pod간 부하를 분산을 kube-proxy가 직접 해서
액세스하려는 포드가 응답하지 않으면 다른 포드를 선택할 수 있었음.
하지만 iptables 규칙은 처음 선택한 Pod 응답하지 않는 경우
다른 Pod를 자동으로 재시도하는 메커니즘이 없음.
즉
userspace mode = pod 하나로 request를 보내는데 실패하면 다른 pod로 연결을 재시도
iptables mode = request를 보내는데 실패하면 재시도 하지 않음.
[2]
Service Object에 해당하는 pod가 다수인 경우
로드밸런싱 알고리즘이 아닌 랜덤으로 선택하게 됨.
[3]
Kubernetes의 리소스의 확장 성 또한 중요한 부분임.
iptables는 순전히 방화벽 목적으로 설계되었기 때문에
수만 개의 서비스로 확장하는데 문제가 있음.
Kubernetes는 release v1.6에서 이미 5000 개의 Node를 지원하지만
한 가지 예를 들어 5000 Node를 가지고있는 kubernetes cluster에
NodePort Type의 Service object를 2000개 사용하고 각 Service object에 매칭되는
10개의 Pod가있는 경우
각 Worker Node에 최소 20000개의 iptable 레코드가 생성되어
이로인해 linux kernel에 과부하가 가서 병목 현상이 발생할 수 있음.
IPVS Mode
IPVS Mode는 Linux kernel에 있는 L4(Transport Layer) LoadBalancer인 IPVS 기술을 사용함.
kube-proxy를 IPVS Mode로 변경하기 전에 IPVS를 사용가능한 환경으로 설정해야함.
iptables 보다 빠르고 좋은 성능을 제공하고 다양한 로드밸런싱 알고리즘을 지원함.
IPVS Mode에서 kube-proxy의 역할은
kubernetes cluster에 생성/삭제되는 Service object와 Pod를 파악하고
파악한 정보에 따라 IPVS 규칙을 설정하는 것임.
client로 부터 오는 request는 Netfilter 통해 IPVS전달되어
IPVS가 모든 Networking 작업을 처리해서 request를 Pod로 전달함.
이 경우 사용되는 IPVS의 Tunneling의 경우 NAT로 동작됨
지원되는 로드밸런싱 알고리즘
(해당 목록 중 설정으로 선택해서 사용가능)
- Round-Robin : Default
- Least-Connection
- Destination Hashing
- Source Hashing
- Sortest Expected Delay
- Never Queue
iptables Mode와 비교한 IPVS의 장점.
[1]
IPVS는 서버 상태 확인 및 연결 재시도 등을 지원함.
[2]
IPVS 프록시 모드에서 Kube-proxy는 iptable mode kube-proxy보다
낮은 레이턴시에 트래픽을 리다이렉트하며,
Rule을 동기화할 때 더 좋은 퍼포먼스로 트래픽을 리다이렉트 함.
다른 kube-proxy Mode와 비교해보면, IPVS Mode는 네트워크 트래픽의 좀더 높은 스루풋을 제공함.
그리고
[3]
iptables 단점 항목 3에서 설명하였듯이 iptabes는 방화벽 목적으로 설계되어
Kubernetes cluster를 구성하는 Node의 수가 많아질 경우 병목현상이 발생할 수 있는 문제가 있음.
하지만 Load Balancing과 확장성을 중점으로 설계된 IPVS를 사용하면 이러한 문제를 해결할 수 있음.
IPVS Mode는 다양한 Load Balancing 알고리즘을 지원하고
Netfilter Hook을 기반으로 구현되어서 iptables Mode와 비슷하지만,
Kernel 영억에서 동작하는 Hash Table 방식을 사용하여 효율적인 데이터 구조를 가지고 있어서
내부적으로 거의 무제한 확장이 가능함.
IPVS Mode도 어쩔 수 없이 iptables를 사용해야함(ipset).
kube-proxy IPVS mode에서 IPVS는 Load Balancing은 가능하지만
패킷 Filtering, hairpin-masquerade , SNAT 등등의 작업은 처리 할 수 없음.
그래서 iptables 기능을 최소한으로 사용해야했으며
kube-proxy iptables mode 처럼 많은 룰을 생성하면 안되니
ipset기술을 사용하여 문제를 해결함.
IPVS 설정 주의 사항.
kube-proxy를 IPVS Mode로 실행하려면,
kube-proxy를 시작하기 전에 모든 Node에서 IPVS를 사용 가능하도록 환경을 미리 구성해야함.
kube-proxy가 IPVS Mode로 설정되어 시작하게 되면,
IPVS kernel module를 사용할 수 있는지 확인하고.
IPVS kernel module이 감지되지 않으면,
kube-proxy는 iptables Mode로 변경되어 실행됨.
Networking 과정
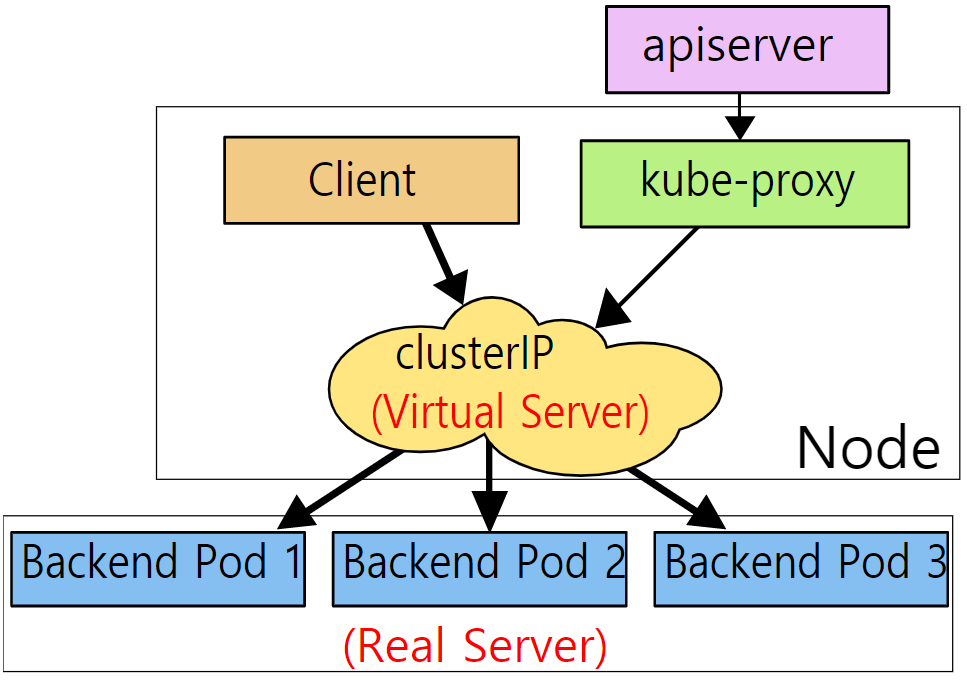
IPVS mode의 Networking 준비 단계
[ 1 ]
IPVS Mode의 kube-proxy는
kube-apiserver와 통신하여 Cluster의 Pod와 Service object의
생성/삭제 상태를 Monitoring 하고있음.
[ 2 ]
Serivce Object가 생성되면
kube-proxy는 IPVS Hash Tables에 해당 Service Object와
Service Object에 매칭되는 Pod정보를 기록함.
[ 3 ]
IPVS Mode의 kube-proxy는
Service Object 과 관련있는 트래픽을 IPVS로 전달하기 위해
iptables ipsec을 설정함.
clusterIP, NodePort, LoadBalancer Type의 패킷을 IPVS로 전달하는
Chain을 생성함.
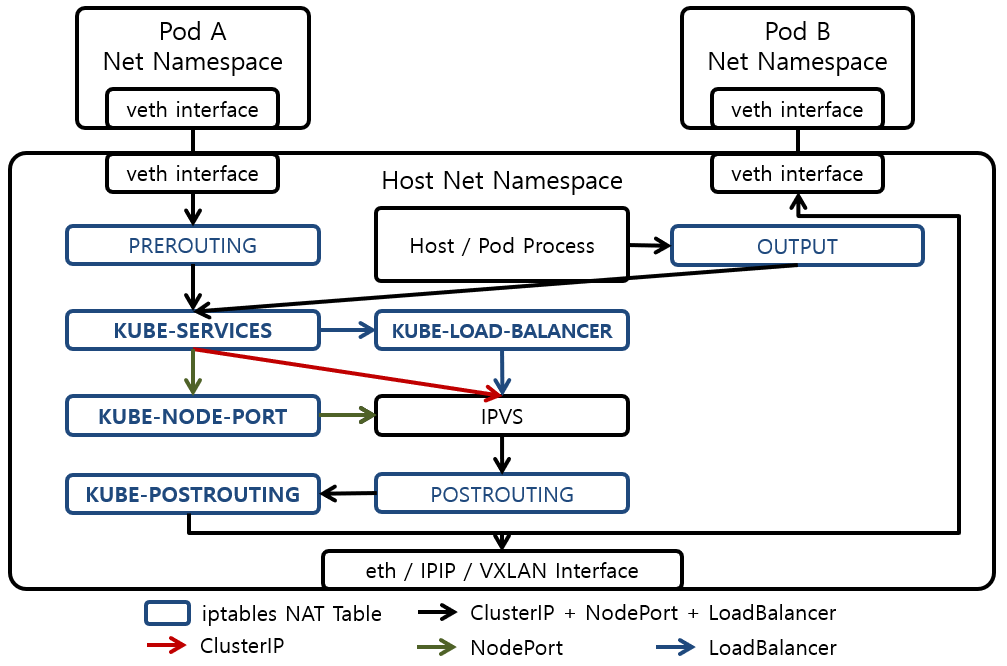
IPVS mode의 Networking 과정
[ 1 ]
Client는 Service Obejct의 Cluster IP로 request 패킷을 보냄.
[ 2 ]
해당 request는 Node(Host)의 iptables 설정에 따라 Linux Kernel Netfiler로 들어옴.
[ 3 ]
Netfilter로 들어온 패킷은 Netfilter Chain 설정에 따라
IPVS로 전달됨
[ 4 ]
IPVS는 해쉬 테이블을 확인하고 매칭되는 Pod로 패킷을 전달함.
만약 매칭되는 Pod가 다수인 경우 설정된 Load Balancing을 통해 선정함.
default LoadBalancer는 Round-Robin임.
더 자세한 Service Object Type에 대한 Networking 과정
iptables 동작을 자세히 표현한 그림.
Load Balancing 알고리즘 설명
Round Robin (RR)
리얼서버를 순차적으로 선택해간다. 모든 서버로 균등하게 처리가 분산됨.
Weighted Round Robin (WRR)
rr과 같지만 가중치를 더해서 분산비율을 변경함.
가중치가 큰 서버일 수록 자주 선택되므로
처리능력이 높은 서버는 가중치를 높게 설정하는 것이 좋음.
Least-Connection (LC)
접속수가 가장 적은 서버를 선택.
어떤 알고리즘을 사용하면 좋을지 모를 경우 보통 사용함.
Weighted Least-Connection (WLC)
lc 방식에 가중치(Ci/Wi)를주어 특정 서버에 더 많은 작업을 할당하는 방식
구체적으로는 "(접속수+1)/가중치" 가 최소가 되는 서버를 선택하므로
처리능력이 높은 서버는 가중치를 크게 하는 것이 좋음.
Destination Hashing (DH)
목적지 IP 주소를 기반으로 해시함수를 통한
해시값을 계산하여 분산대상 리얼서버를 선택함.
Source Hashing (SH)
출발지 IP 주소를 기반으로 해시함수를 통한
해시값을 계산하여 분산대상 리얼서버를 선택함.
Shortest Expected Delay (SED)
가장 응답속도가 빠른 서버를 선택함.
그렇다고 해도 서버에 패킷을 날려 응답시간을 계측하는 것이 아닌,
상태가 Established인 접속수가 가장 적은 서버를 선택함.
wlc와 거의 동일하게 동작하지만
wlc에서는 Established 이외의 상태(TIME_WAIT, FIN_WAIT)인 접속수도 포함함.
Never Queue (NQ)
sed와 동일한 알고리즘이지만 active 접속수가 0인 서버를 최우선으로 선택함.
Locality-Based Least-Connection (LBLC)
접속수가 가중치로 지정한 값을 넘기기 전까지는 동일한 서버를 선택함
접속수가 가중치로 지정한 값을 넘어선 경우에는 다른 서버를 선택함
모든 서버의 접속수가 가중치를 넘을 경우 마지막에 선택된 서버가 계속 선택됨.
Locality-Based Least-Connection with Replication (LBLCR)
lblc와 거의 같지만 모든 서버의 접속수가 가중치로 지정한 값을 넘을 경우 접속수가 가장 적은 서버가 선택됨.
제 글을 복사할 시 출처를 명시해주세요.
글에 오타, 오류가 있다면 댓글로 알려주세요! 바로 수정하겠습니다!
참고
[kube-proxy mode 설명]
https://ssup2.github.io/theory_analysis/Kubernetes_Service_Proxy/
https://kubernetes.io/docs/concepts/services-networking/service/#virtual-ips-and-service-proxies
https://arisu1000.tistory.com/27839
https://cloud.tencent.com/developer/article/1501772
[kubernetes IPVS]
https://kubernetes.io/blog/2018/07/09/ipvs-based-in-cluster-load-balancing-deep-dive/
https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/ipvs/README.md
[ LVS / IPVS ]
https://ssup2.github.io/theory_analysis/Linux_LVS_IPVS/
[Load Balancing 알고리즘]
https://tisiphone.tistory.com/257
'Kubernetes > 네트워크' 카테고리의 다른 글
| Kubernetes NodePort Networking 분석 (kube-proxy : iptable mode) (1) | 2021.05.06 |
|---|---|
| Kubernetes kube-proxy IPVS Mode 설정 (1) | 2021.03.19 |
| Pod의 veth (Virtual Ethernet Interface) 장치 찾기 (0) | 2020.11.07 |
| Kubernetes Network Policy (0) | 2020.11.07 |
| Kubernetes Network (Ingress) (2) | 2020.08.12 |